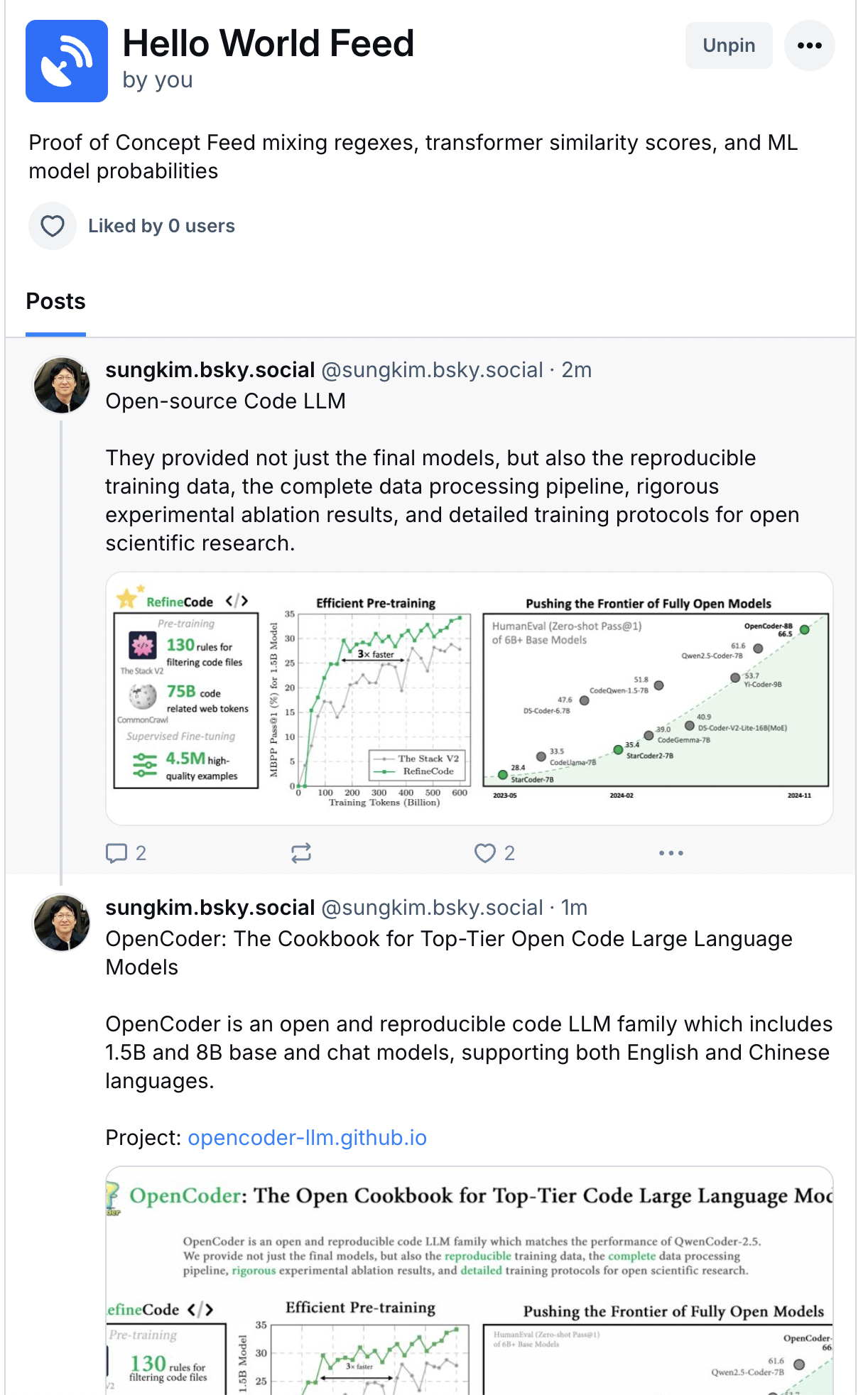
Democratizing Algorithmic Feeds on Bluesky
If the original sin of Web 1.0 was the pop-up ad, the original sin of web 2.0 was the move to algorithmic feeds.…
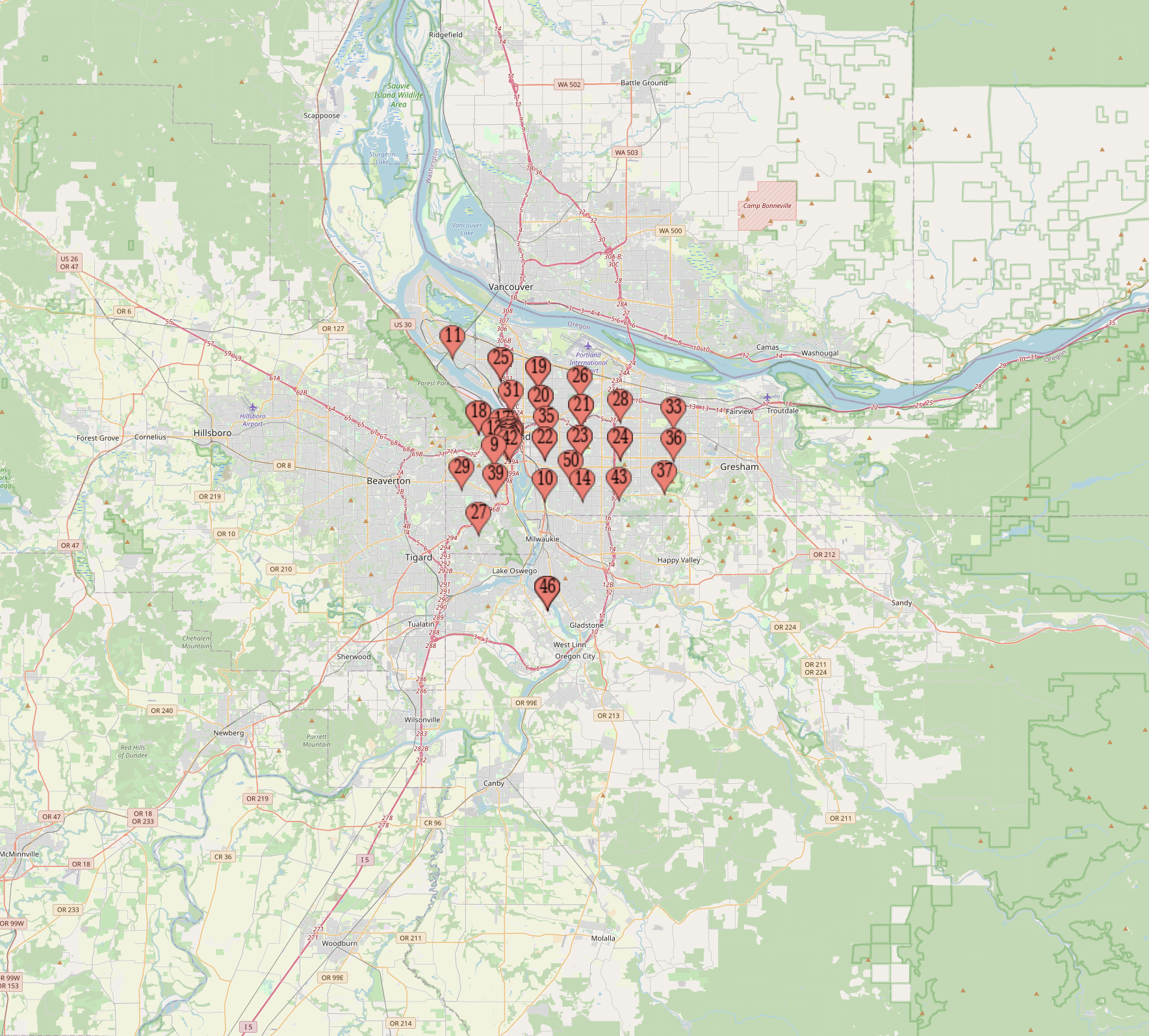
How Much Data is Enough for Finetuning an LLM?
There's no shortage of analogies for explaining what an LLM is capable of - one of the best, though, is from this New Yorker article…
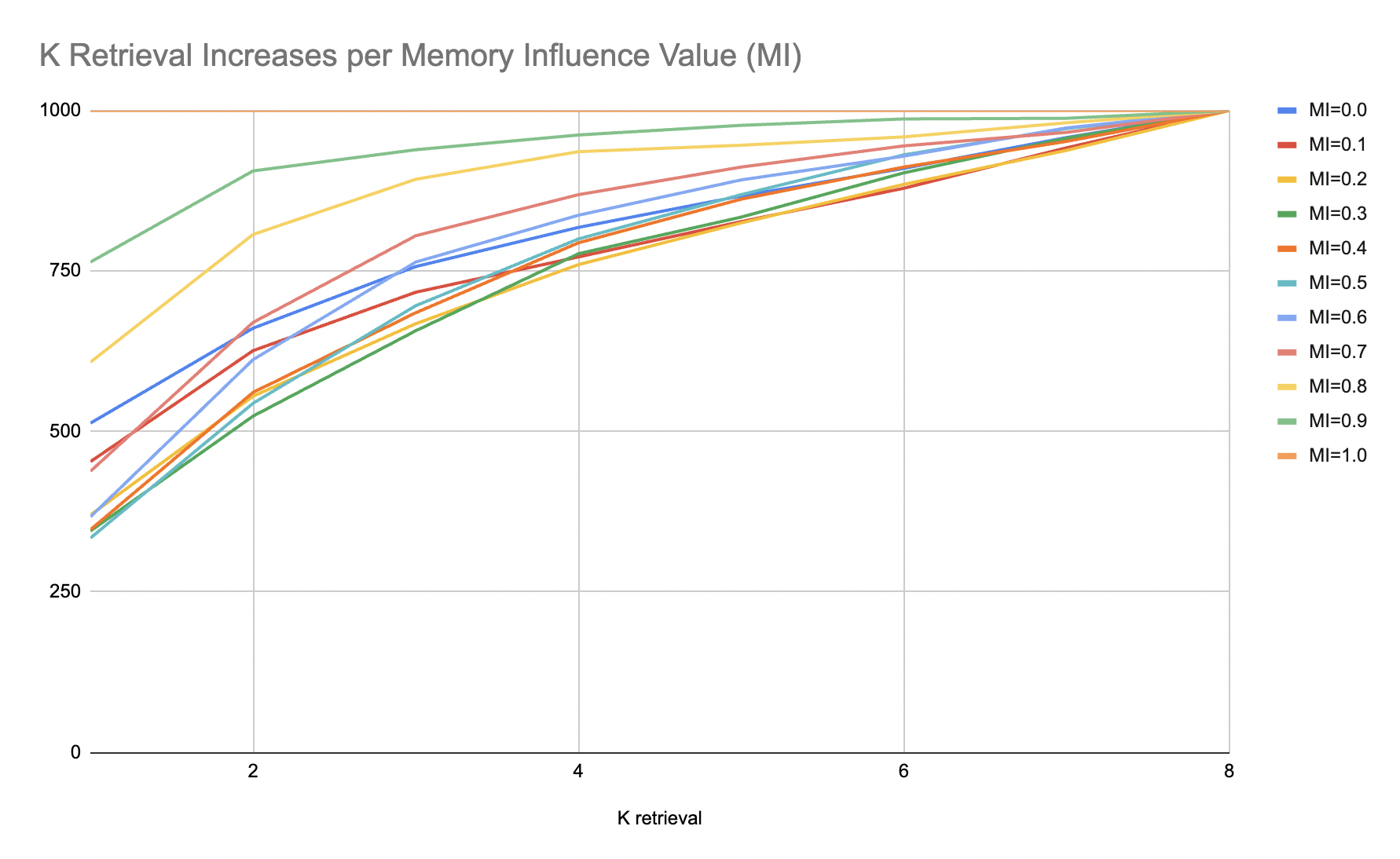
Using Synthetic Data Generators to Measure LSTM Lift
Long short-term memory models (LSTMs) are a family of neural networks that are predominantly used to predict the next value given a historical chain of…
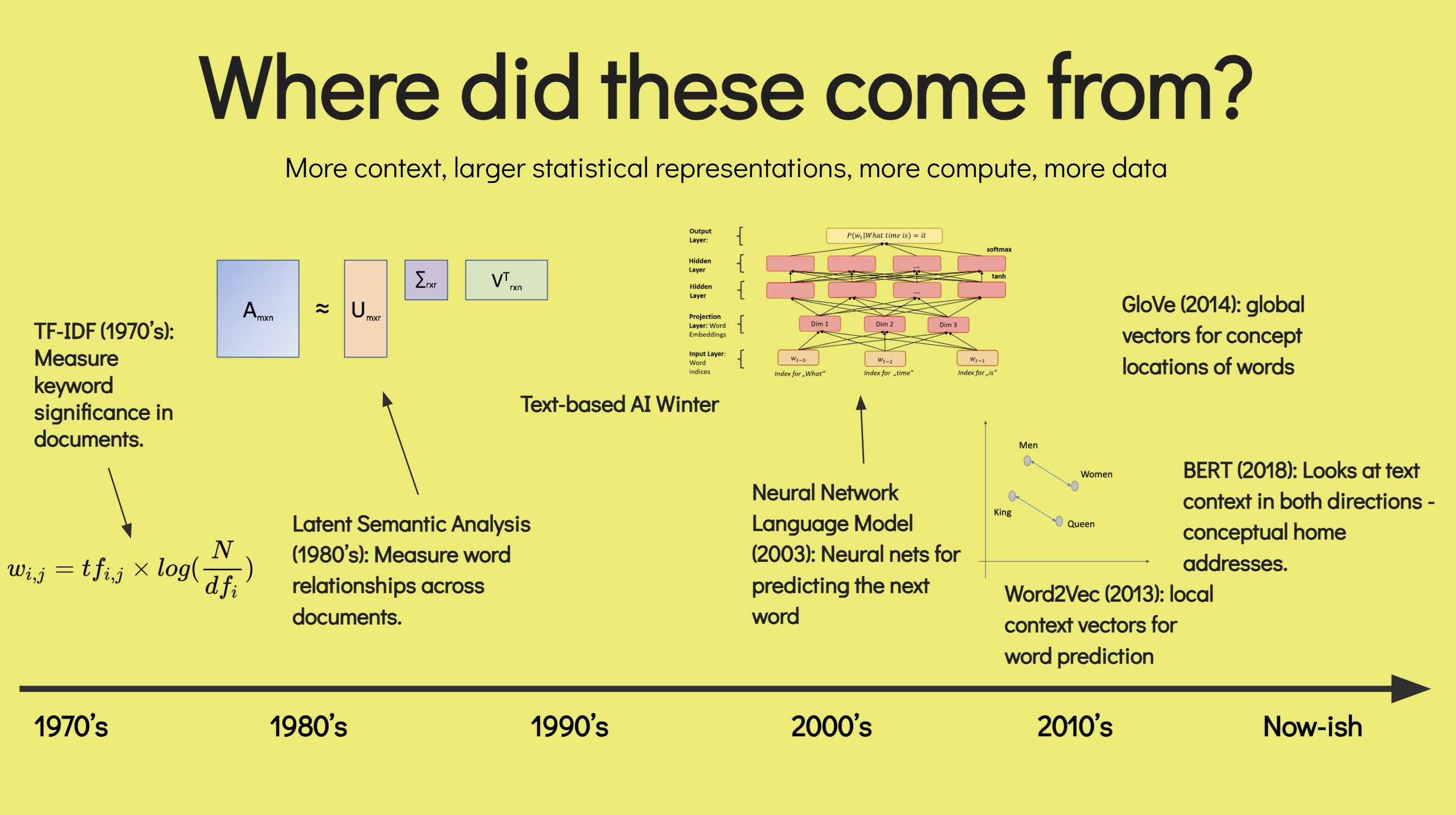
Some supervision required: LLMs at scale in practice
Recently, I gave a talk at the PIE/Autodesk space to help contextualize some thoughts that have been percolating with regards to the nascent introduction…
Leveraging the Helium Network to Deploy Extremely Low Cost Asset Trackers
Over the summer, I got really interested in the Helium network. Unlike many other crypto-backed projects, there was something at least of articulable value being…
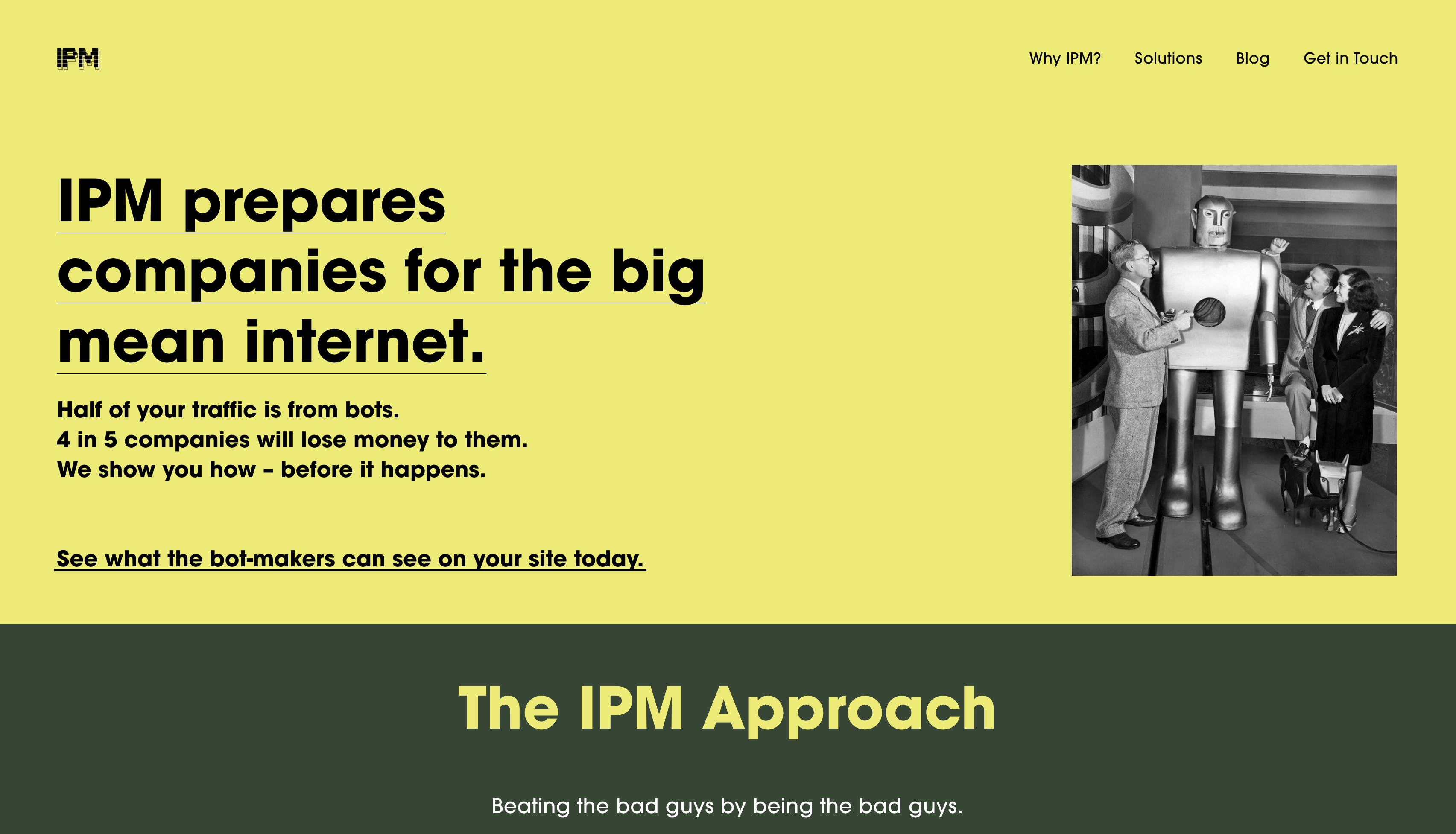
IPM Corporation - The First Sociotechnical Security Firm
Big news! My good friend Tim Hwang and I have started a company, International Persuasion Machines (IPM). Our company is based off several foundational principles:…

SubstackDB: Exploiting Lax Upload Validation to Create Parasitic File Servers
For the past year, I've been increasingly focusing on what I have come to call "sociotechnical security" - whereas "technical security" seeks to identify and…

Predicting Car Auction Prices
About 10 days ago, I saw a post for a ridiculously cute car of a make and model that I previously did not know existed:…
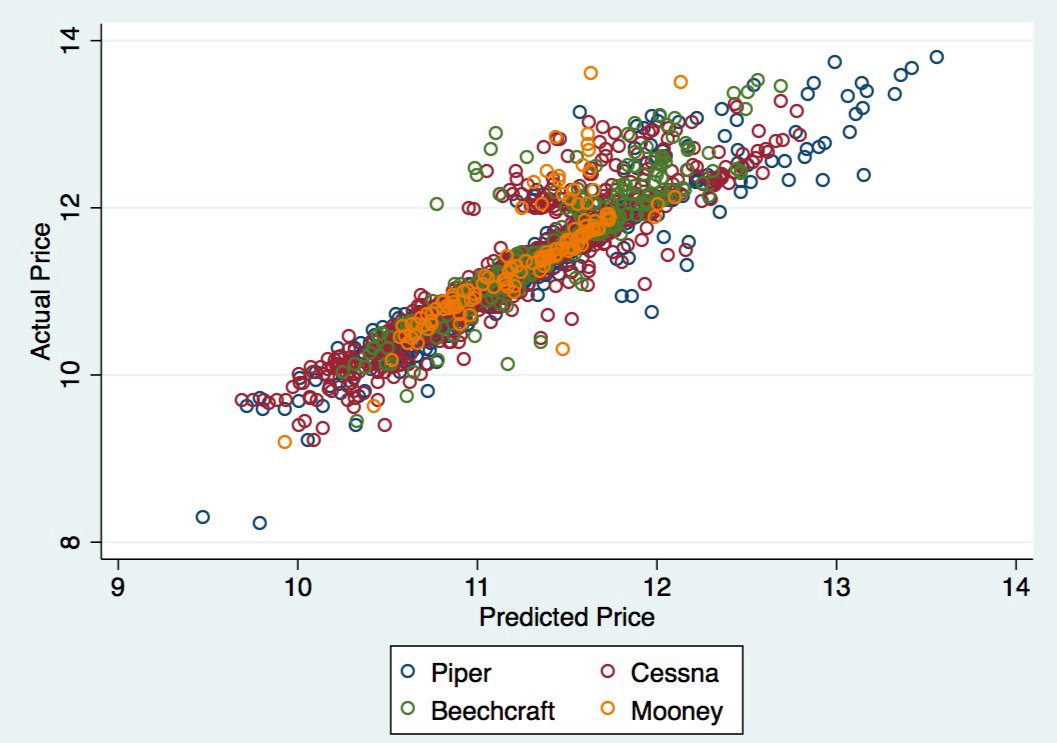
Using ML to automatically detect undervalued planes on Trade-a-Plane.com
@TAP_deals is a bot on Twitter that uses machine learning to extrapolate the estimated value of a plane based on historical trends from listings…

Caveat Emptor, Computational Social Science
Large-Scale Missing Data in a Widely-Published Reddit Corpus As researchers study complex social behaviors at scale with large datasets, the validity of this computational social…

Stop Sign Detector
I bought a Raspberry Pi a while back without much of a plan for what it would ultimately work on. After getting annoyed by a…

@DudeBro538: I'm not Nate Silver but I play him on Twitter
Background On December 5th, the following tweet passed through my timeline: The DudeBro Tournament 2016 pic.twitter.com/z8Ei56dBKX— DudeBroWatch👮🚨 (@DudeBroTourney) December 6, 2016…

Running Random Walks in Amazon Lambda
When I first heard about Amazon Lambda, I was skeptical. It was explained to me as basically "code in the cloud" and my immediate take…
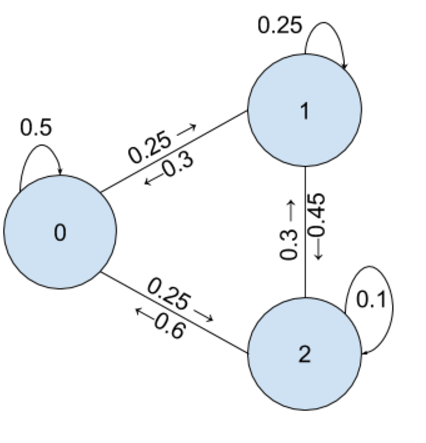
Simulating Random Walks to Predict Network Interventions
Building a Network of Conversation Points Over the summer, I spent the summer working with a good friend Gilad Lotan as a data science intern…

Modeling the Contemporary Social Internet
This last week, I attended a several day seminar about combating online harassment, saw an academic friend get an award for her book on trolling…

Everything is a Nail: Disinterpolation with Markov Networks
Back to Rare Pepe Inc As you may remember from several previous posts, I like to put the things I'm building within a clear frame…

Estimating Instagram’s Actual Population Statistics
TL;DR: Monthly Active Users is a silly, desperate metric. When Instagram says they have 400 million monthly active users, they mean to say they…
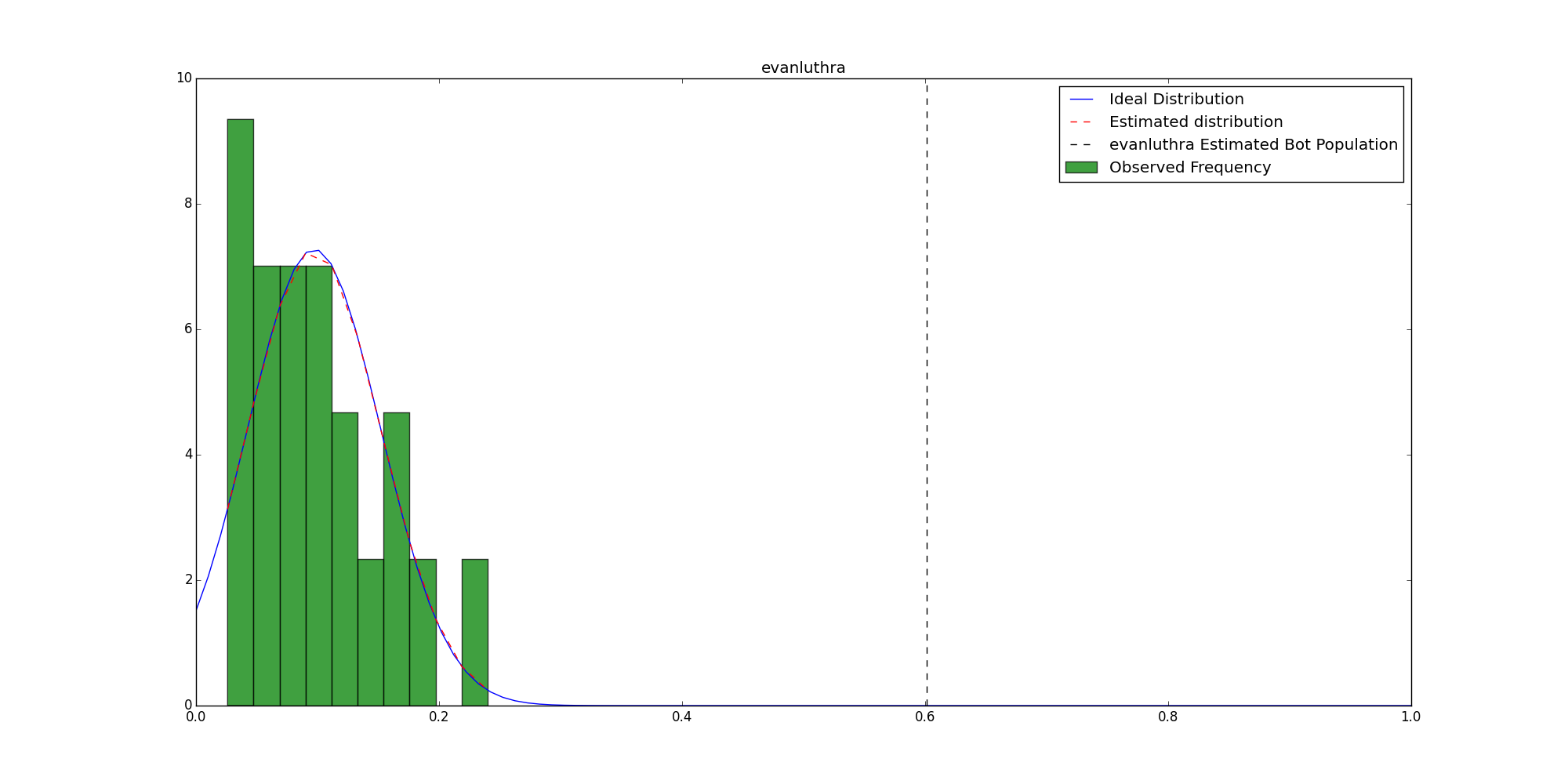
Estimating Bot Populations following the Rich Kids of Instagram
Background About a week ago, someone mentioned me in a post on Facebook asking if I knew any way to determine if an account on…

Maximizing User Growth with Appropriate Measurement
It’s Wednesday, January 1, 2014. You’re the CEO of Rare Pepes, Inc. Your company thinks that Rare Pepes are important, and you want…

Building an Identity Function for Viral Growth
In mathematics, an identity function is one which satisfies a seemingly terribly boring equation: f(x) = x Right? Super boring. Given some input x, we…

Beyond the Listicle: The Science of Virality
Abstract: The growing abundance of trending stories and un-ignorable zeitgeist moments have turned viral stories into the holy grail of content creation. But what does…

Exploiting networked adoption patterns
Background In a previous post, I talked about the laziness of the term "going viral". In it, I talked about how network scientists would investigate…

When Network Scientists talk about Cat GIFs
Background 88 Years ago, two men tried to explain the conditions under which a catastrophic epidemic succeeds. The goal of their work was to try…
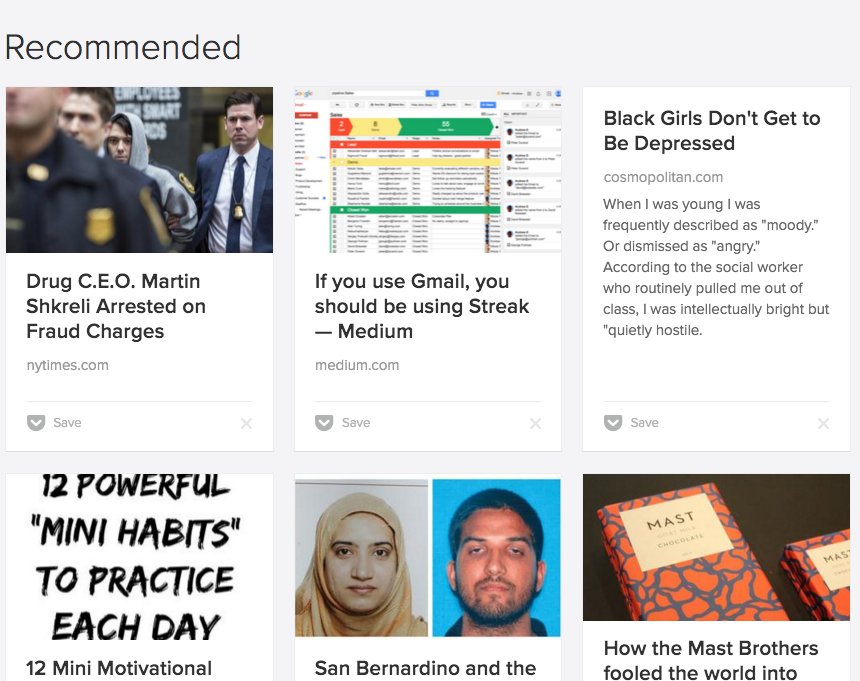
Predicting the News You'll read
Some Background Of the few apps I use, Pocket is probably the one I hold in high regard. Pre-pocket, my browser, like any pre-Pocket user,…
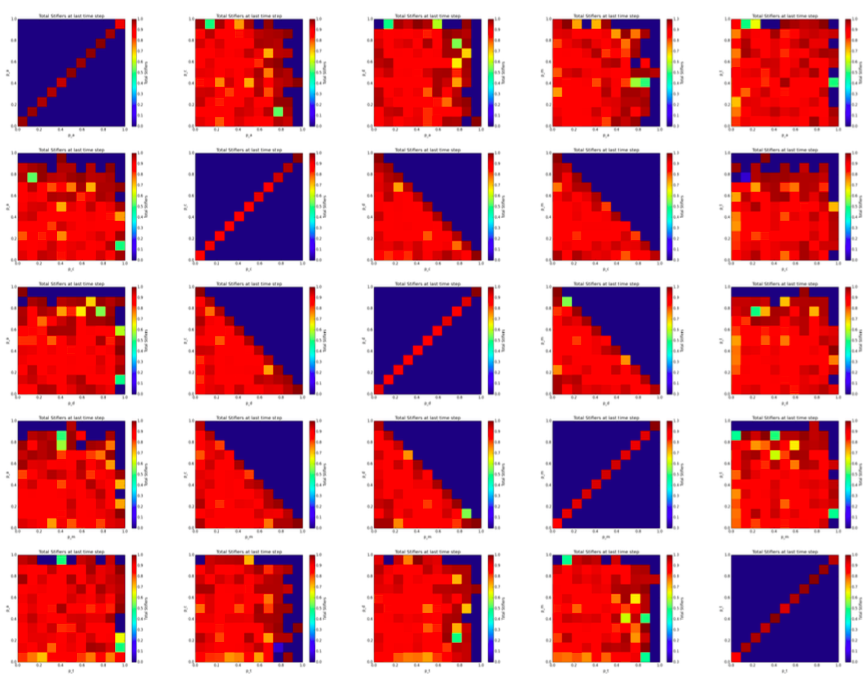
Modeling misclassifications in multilayer networks
Abstract Given two networks and some ties between those two networks, how many of those ties must be correctly assigned in order to ensure an…

All of Reddit's comments, initial skim
Over the past few days, I've had the pleasure of finally downloading /u/Stuck_In_the_Matrix's dataset posted to reddit: Nearly all of the…

Trace Interview Workshop, SMSociety '15
Elizabeth Dubois and I just did a workshop covering largely her method of "trace interviews" that she has pioneered alongside Heather Ford - and I…
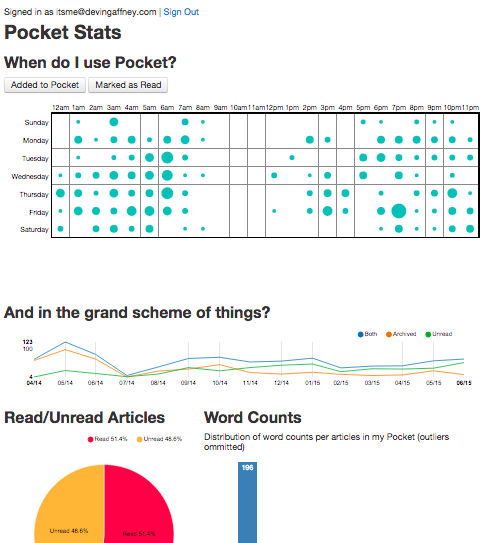
Interactive Pocket Infographic
How do you interact with news? Do you read in the morning, or save it until right before bed? In my case, I apparently habitually…
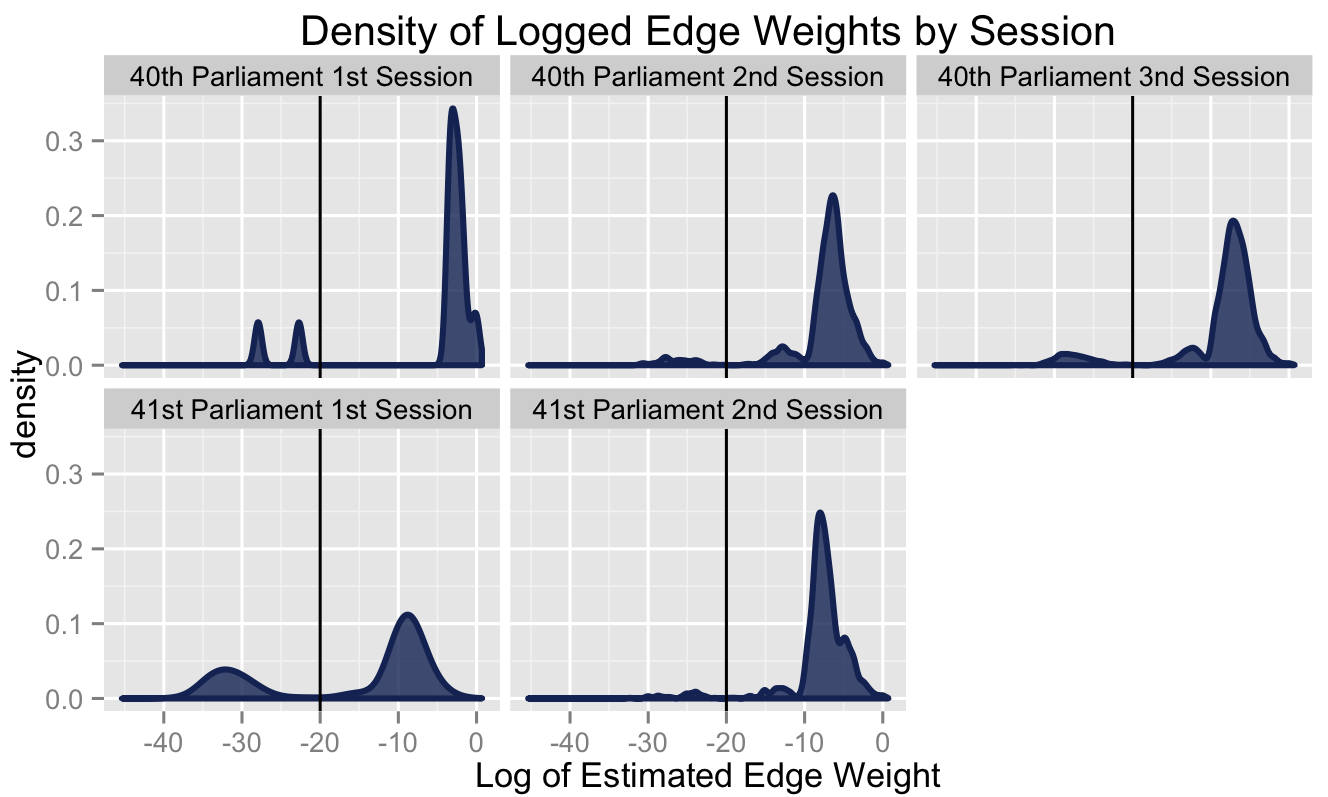
Exploring the Role of Geographic Diffusion in Viral Cascades
From my talk at CSSS15 at Northwestern about the role of initial geographic diffusion of a viral cascade and the impact that has on the…
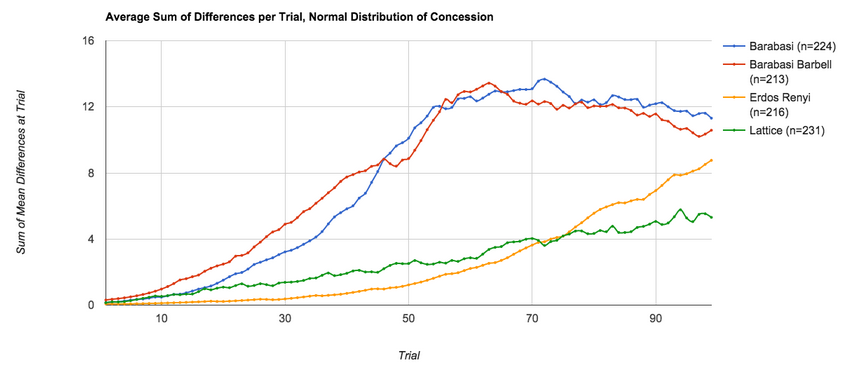
Modeling Opinion Diffusion in Online Social Networks
A talk that was to be given at SUNBELT XXXV - unfortunately multiple situations conspired to prevent me from showing this research, but someday! For…
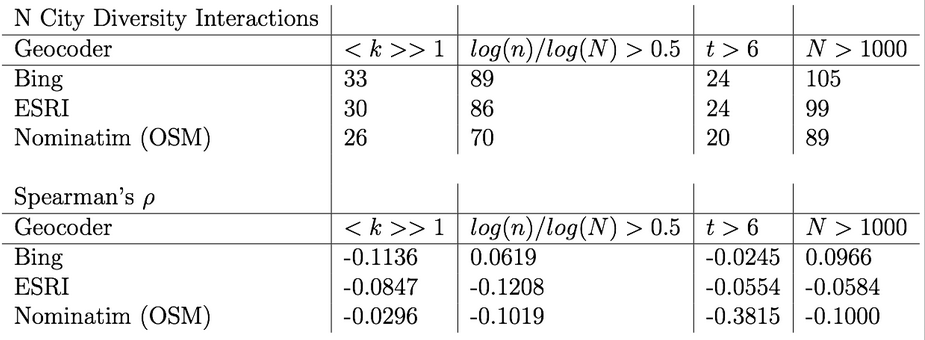
Lobbying Strategy Diffusion in Canadian Politics
Studies of lobbying in North America have tended to focus largely on activities and strategies of interest groups and their lobbyists in American politics. However,…

The Anatomy Of Viral Content And Internet Outrage
Hear an interview with me and Robin Young on WBUR's Here and Now - we talk about #TheDress, Internet Outrage or Public Shame, and how…

Gephi Tutorial
A Gephi tutorial presented to students at Northeastern. To get all the data required to run along the tutorial, click here.…
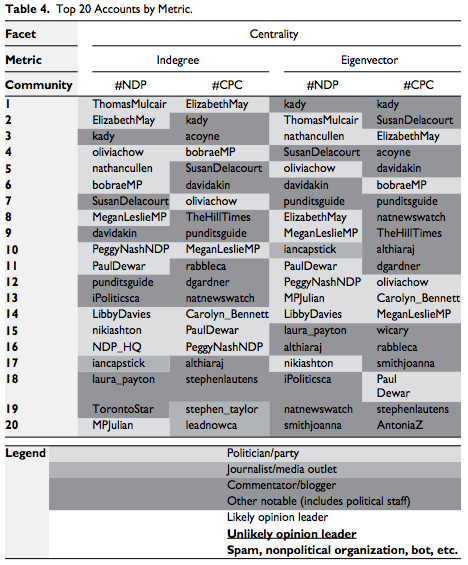
The Multiple Facets of Influence
This study compares six metrics commonly used to identify influential players in two of Canada’s largest political Twitter communities based on the users, and…

Data Collection on Twitter
Cornelius Puschmann and I contributed a chapter to the book "Twitter And Society" - our chapter is "Data Collection on Twitter" and is a dense…

Location! The Importance of Geo-data
On March 12th, 2013, Mark Graham (my former boss at Oxford Internet Institute and permanent friend for life), Monica Stephens, and Catherine D’Ignazio participated…

Game or measurement? Algorithmic transparency and the Klout score
Cornelius Puschmann and I wrote up an interesting and short paper about serious complaints with Klout, a now less important, but at the time very…
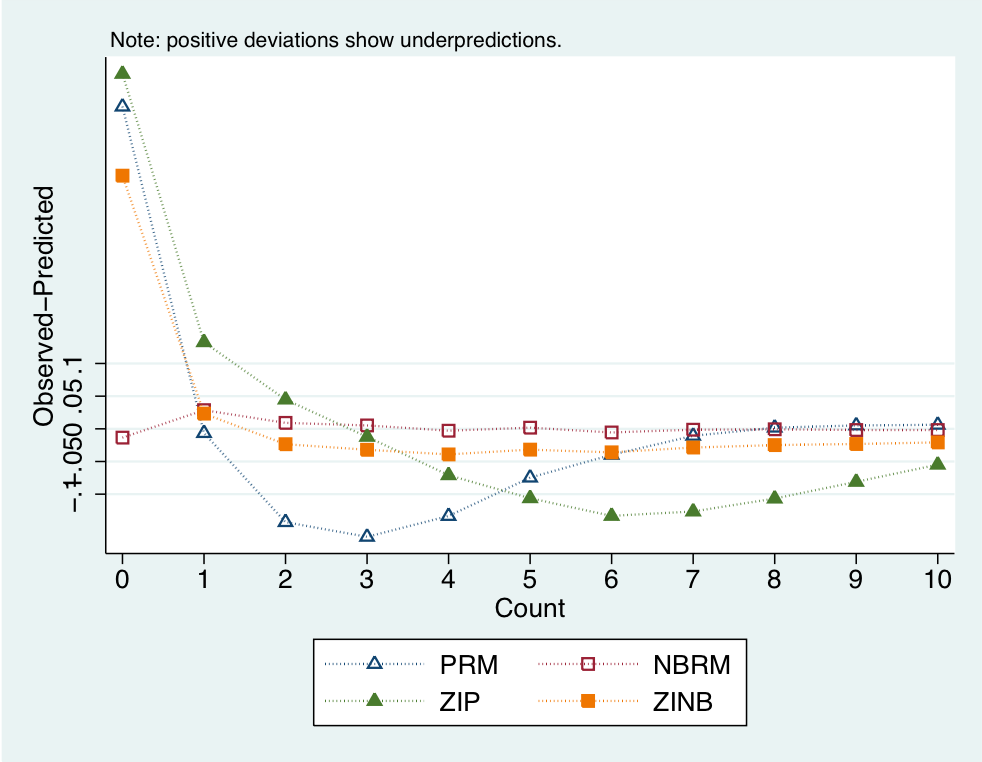
Determining the Importance of Geography on Twitter
The theoretical annihilation of geography as an intrinsic consideration in the transfer of information is one of the most salient features of the modern communications…
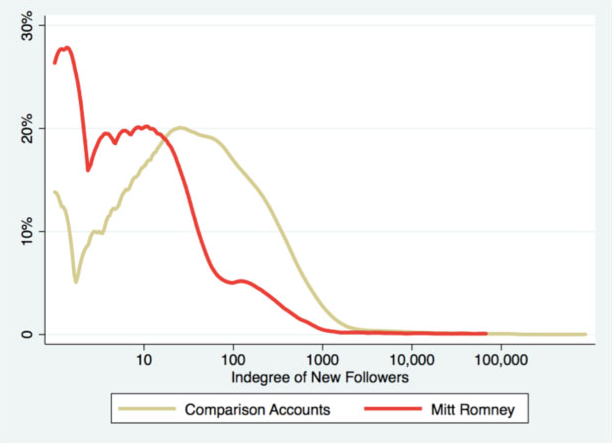
Statistical Probability That Mitt Romney’s New Twitter Followers Are Just Normal Users: 0%
This one time, Zander Furnas and I were at a bar and were trying to figure out how to prove that someone had bought followers…
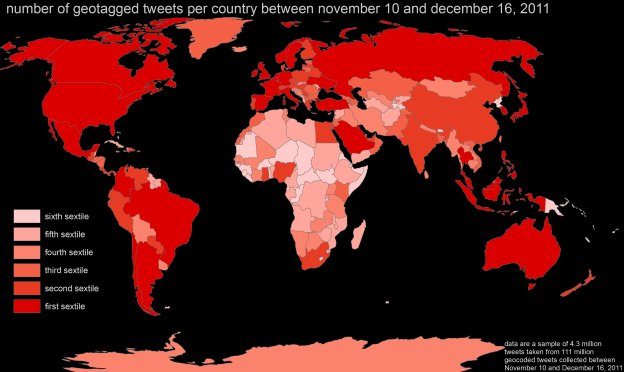
Where in the world are you?
Mark Graham, Scott Hale, and I have written an article about the geolinguistic contours of Twitter mostly for the purpose of improving and exploring methodological…
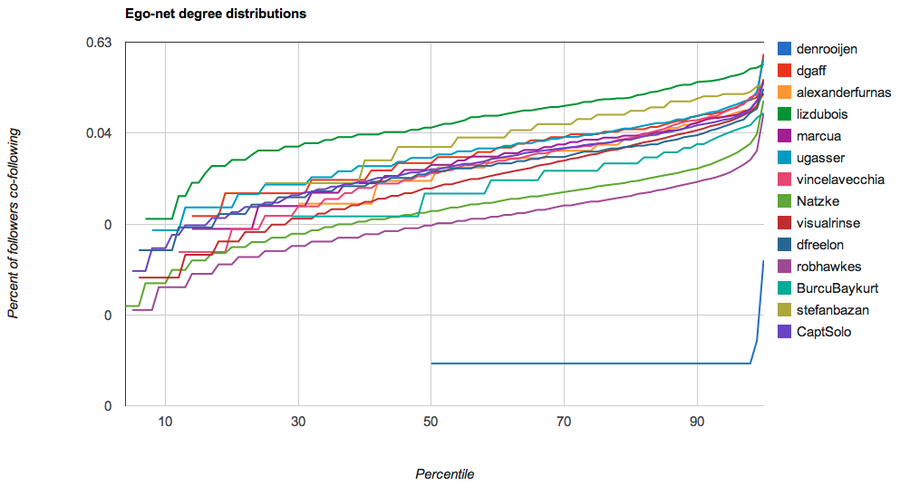
Detecting cheaters on Twitter via ego-net degree distributions of followers
If you know me beyond this post, you know that I’m currently a master’s candidate at Oxford Internet Institute. As part of this,…
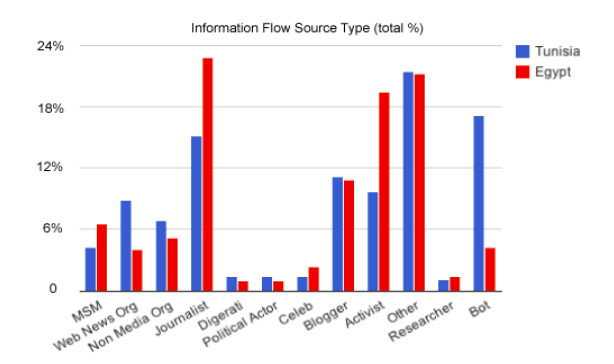
The Revolutions Were Tweeted
Gilad Lotan, Erhardt Graeff, Mike Ananny, Ian Pearce, danah boyd and I have written an article about the Arab Spring and the role of Twitter…

Breaking Bin Laden: visualizing the power of a single tweet
Gilad Lotan, Cherie Meyer, and myself recently wrote up a piece for SocialFlow, a company that I am contracting/consulting for currently. We wanted to…

Android Lock Combinations
This morning, my girlfriend asked me for her phone when she woke up. She had the cell phone on the side of the bed, and…

The Data Your Data Could Smell Like
Note: This document is originally from work conducted with Ian Pearce and has been transcribed here for posterity. Read on for the original work conducted…
#IranElection: Quantifying Online Activism
For the final year of undergrad in college, I wanted to narrow down to an insanely specific degree and study the impact (if any) of…

GPS Balloon
The college I go to decided that they were going to fire our only computer science professor; I think that’s when we started really…

Wikipedia Network Maps
I have been working on a really exciting project with Ian Pearce and Max Darham that attempts to visualize Wikipedia. Our idea was as such:…

Contact Me
e-mail: chars = ['.', '@', 'a', 'c', 'd', 'e', 'f', 'g', 'i', 'm', 'n', 'o', 's', 't', 'v', 'y'] [8,13,12,9,5,…